API
Declarative
The High-Level API is declarative. What does that mean? All you have to do is specify the state that you want the data in, and then the backend executes all of the tedious data wrangling needed to achieve that state. It’s like Terraform for machine learning.
from aiqc.orm import Dataset
from aiqc.mlops import *
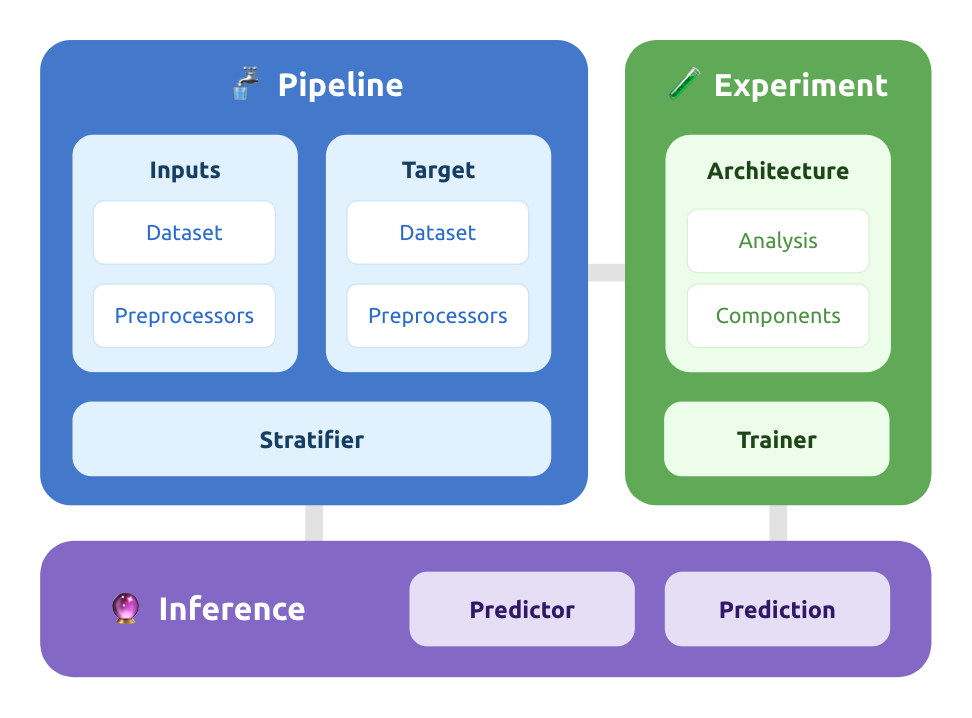
Pipelinedeclares how to preprocess data.Experimentdeclares variations of models to train and evaluate.Inferencedeclares new samples to predict.
Reference the tutorials to the see the high level API in action for various types of data and analysis. It’s declarative nature makes it easy to learn by reading examples as opposed to piecing together which arguments point to each other. Check back here if you get stuck.
Why so many pointer variables? – Under the hood, the High-Level API is actually chaining together a workflow using the object-relational model (ORM) of the Low-Level API. Many of the classes provided here are just an easier-to-use versions of their ORM counterparts.
1. Pipeline
Declares how to prepare data. The steps defined within the pipeline are used at multiple points in the machine learning lifecycle:
Preprocessing of training and evaluation data.
Caching of preprocessed training and evaluation data.
Post-processing (e.g. decoding) during model evaluation.
Inference: encoding and decoding new data.
Pipeline(
inputs
, target
, stratifier
, name
, description
)
Argument |
Type |
Default |
Description |
|---|---|---|---|
inputs |
list(Input) |
Required |
Input - One or more featuresets |
target |
Target |
None |
Target - Leave blank during unsupervised/ self-supervised analysis. |
stratifier |
Stratifier |
None |
Stratifier - Leave blank during inference. |
name |
str |
None |
An auto-incrementing version will be assigned to Pipelines that share a name. |
description |
str |
None |
Describes how this particular workflow is unique. |
It is possible for an
Inputand aTargetto share the sameDataset. TheInput.include_columnsandInput.exclude_columnswill automatically be adjusted to excludeTarget.column.
Returns |
Splitset instance as seen in the Low-Level API. We will use this later as the Trainer.pipeline argument. |
1a. Input
These are the features that our model will learn from.
This is a wrapper for Feature and all of its preprocessors in the Low-Level API.
Input(
dataset
, exclude_columns
, include_columns
, interpolaters
, window
, encoders
, reshape_indices
)
Argument |
Type |
Default |
Description |
|---|---|---|---|
dataset |
Dataset |
Required |
Dataset from Low-Level API |
exclude_columns |
list(str) |
None |
The columns from the Dataset that will not be used in the featureset |
include_columns |
list(str) |
None |
The columns from the Dataset that will be used in the featureset |
interpolaters |
list(Input.Interpolater) |
None |
|
window |
Input.Window |
None |
|
encoders |
list(Input.Encoder) |
None |
|
reshape_indices |
tuple(int/str/tuple) |
None |
Reference |
Both
exclude_columnsandinclude_columnscannot be used simultaneously.
1ai. Input.Interpolater
Used to fill in the blanks in a sequence.
This is a wrapper for FeatureInterpolater in the Low-Level API.
Input.Interpolater(
process_separately
, verbose
, interpolate_kwargs
, dtypes
, columns
)
1aii. Input.Window
Used to slice and shift samples into many time series windows for walk-forward/ backward analysis.
This is a wrapper for Window in the Low-Level API.
Input.Window(
size_window
, size_shift
, record_shifted
)
1aiii. Input.Encoder
Used to numerically encode data.
This is a wrapper for FeatureCoder in the Low-Level API.
Input.Encoder(
sklearn_preprocess
, verbose
, include
, dtypes
, columns
)
1b. Target
What the model is trying to predict.
This is a wrapper for Label and all of its preprocessors in the Low-Level API.
Target(
dataset
, column
, interpolater
, encoder
)
Argument |
Type |
Default |
Description |
|---|---|---|---|
dataset |
Dataset |
Required |
|
column |
list(str) |
None |
The column from the Dataset to use as the target. |
interpolater |
Target.Interpolater |
None |
|
encoder |
Target.Encoder |
None |
1bi. Target.Interpolater
Used to fill in the blanks in a sequence.
This is a wrapper for LabelInterpolater in the Low-Level API.
Target.Interpolater(
process_separately
, interpolate_kwargs
)
1bii. Target.Encoder
Used to numerically encode data.
This is a wrapper for LabelCoder in the Low-Level API.
Target.Encoder(
sklearn_preprocess
)
1c. Stratifier
Used to slice the dataset into training, validation, test, and/or cross-validated subsets.
This is a wrapper for Splitset in the Low-Level API.
Stratifier(
size_test
, size_validation
, fold_count
, bin_count
)
2. Experiment
Used to declare variations of models that will be trained.
Experiment(
architecture
, trainer
)
Argument |
Type |
Default |
Description |
|---|---|---|---|
architecture |
Architecture |
Required |
|
trainer |
Trainer |
Required |
Returns |
Queue instance as seen in the Low-Level API. |
2a. Architecture
The model and hyperparameters to be trained.
This is a wrapper for Algorithm in the Low-Level API, with the addition of hyperparameters.
Architecture(
library
, analysis_type
, fn_build
, fn_train
, fn_optimize
, fn_lose
, fn_predict
, hyperparameters
)
2b. Trainer
The options used for training.
This is a wrapper for Queue in the Low-Level API, with the addition of pipeline.
Trainer(
pipeline
, repeat_count
, permute_count
, search_count
, search_percent
)
3. Inference
Used to preprocess new samples, run predictions on them, decode the output, and, optionally, evaluate the predictions.
Inference(
predictor
, input_datasets
, target_dataset
, record_shifted
)
Argument |
Type |
Default |
Description |
|---|---|---|---|
predictor |
Predictor |
Required |
Predictor to use for inference |
input_datasets |
list(Dataset) |
Required |
New Datasets to run inference on. |
target_dataset |
Dataset |
None |
New Datasets for scoring inference. Leave this blank for pure inference where no metrics will be calculared. |
record_shifted |
bool |
False |
Set this to True for scoring during unsupervised time series inference |
We don’t need to specify fully-fledged
InputsandTargetobjects because thePipelineof thepredictorobject will be reused in order to process these new datasets.
Returns |
|