Declarative, Multi-Modal AI
End-to-end API & UI for the deep learning lifecycle
Star on GitHub

Write 90% less data-wrangling code with declarative pipelines
| Tabular(2D) | Sequence(3D) | Image(4D) | |
| Classification(binary, multi) | ✓ | ✓ | ✓ |
| Quantification(regression) | ✓ | ✓ | ✓ |
| Forecasting(multivariate) | ✓ | ✓ | ✓ |
AIQC's structured protocols automate the tedious pre-processing and post-processing steps that are unique to each type of data and analysis.
This enables teams to stay focused on data science, as opposed to writing DIY software that manages the machine learning lifecycle and all of its edge cases.
Goodbye, `X_train, y_test`.
Hello, object-oriented AI.








>
<
Automated visualizations for each split & fold of every model
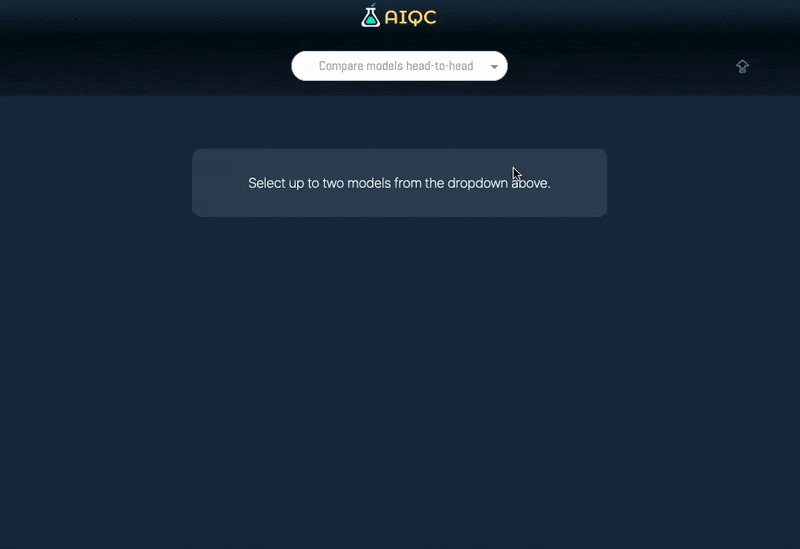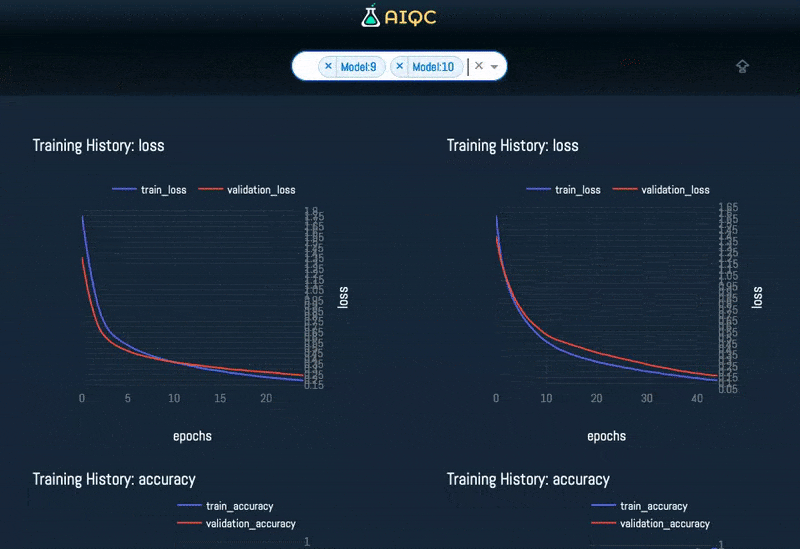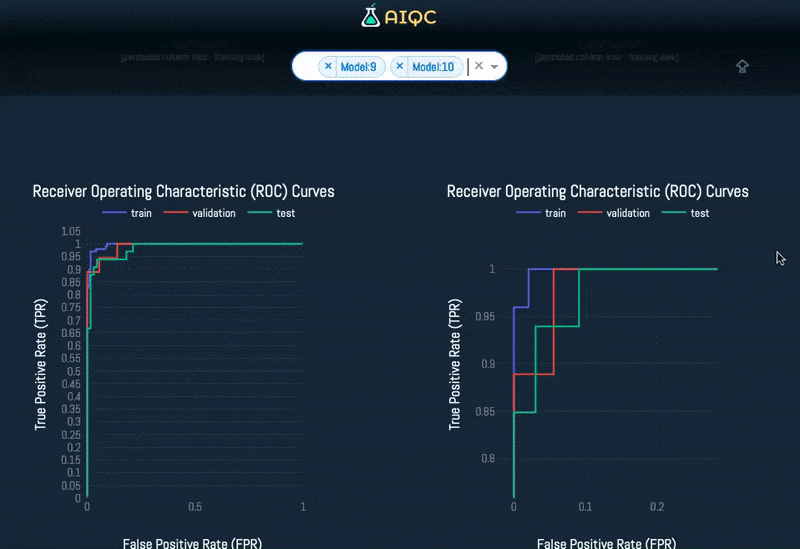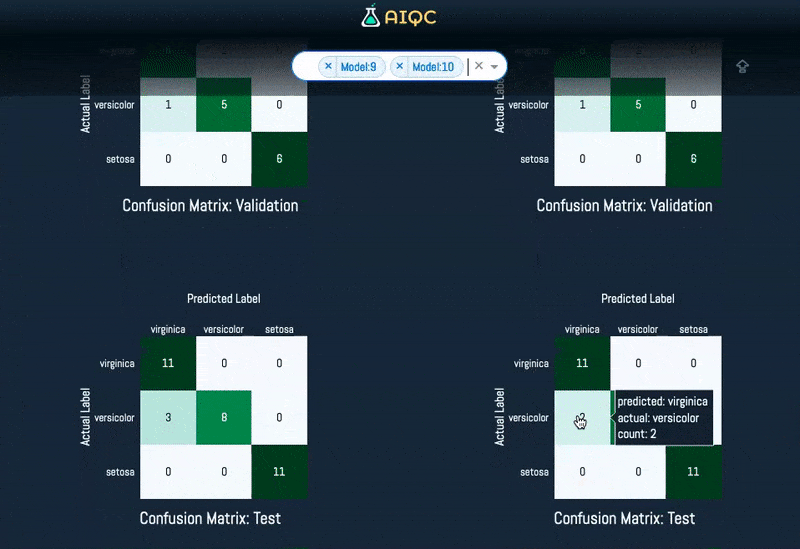
Quality Control (QC) best practices are built into the framework
| Train | Validation | Test | Inference |
| Prevent evaluation bias with 3-way+ stratification. | Validate the structure of new samples. | ||
| Prevent data leakage by only using preprocessing information derived from the training split/fold. | Prevent data drift by using original preprocessors. | ||
| Prevent overfitting by evaluating each split/ fold of every model | Detect model rot by reevaluating with supervised datasets. | ||
| Ensure reproducibility by using a standardized framework that records the entire workflow. | |||
AIQC
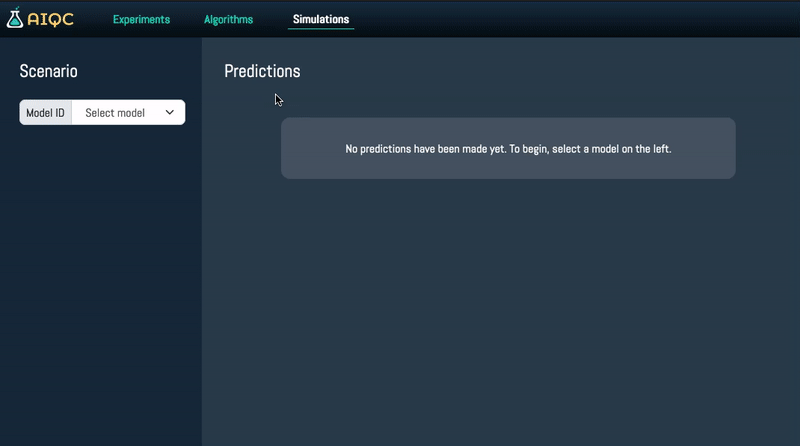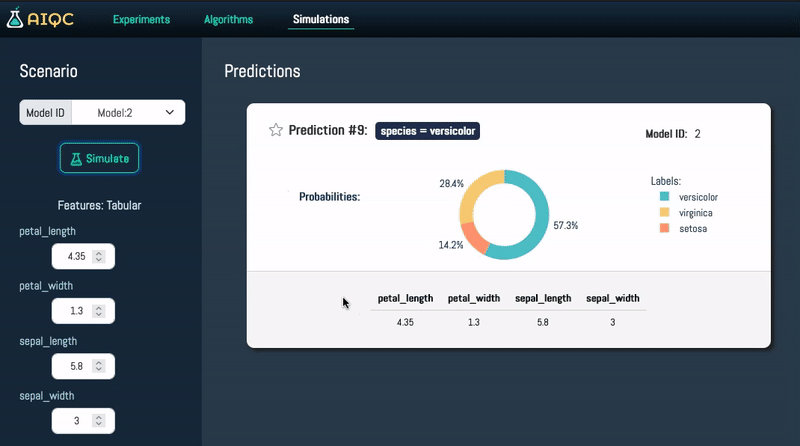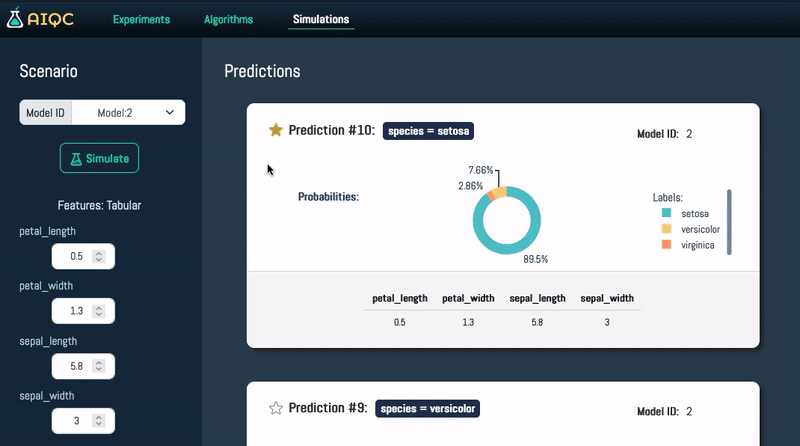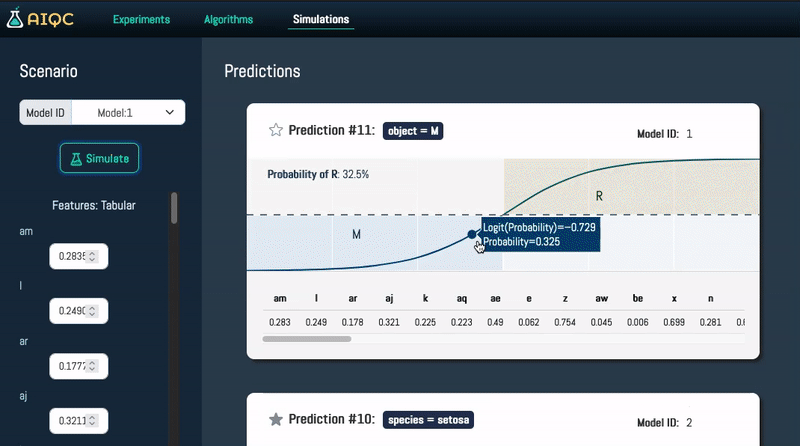
Conduct what-if analysis to simulate virtual outcomes

Let's get started!
→ Use Cases & Tutorials